tracing: reorganize benchmarks for comparability #2178
Merged
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Currently, `tracing`'s benchmark suite benchmarks the same behaviors (e.g. creating a span, recording an event, etc) across a handful of cases: with no default dispatcher, with a global default, and with a scoped (thread-local) default. We use criterion's `benchmark_group` to represent each kind of dispatcher, and `bench_function` for each behavior being measured. This is actually kind of backwards relative to how Criterion is _supposed_ to be used. `bench_function` is intended for comparing different implementations of the *same* thing, with the `benchmark_group` representing what's being compared. If we inverted the structure of these benchmarks, Criterion would give us nicer plots that would allow comparing the performance of each dispatch type on the same task. This PR reorganizes the benchmarks so that each behavior being tested (such as entering a span or recording an event) is a `benchmark_group`, and each dispatch type (none, global, or scoped) is a `bench_function` within that group. Now, Criterion will generate plots for each group comparing the performance of each dispatch type in that benchmark. Unfortunately, this required splitting each benchmark type out into its own file. This is because, once we set the global default dispatcher within one benchmark group, it would remain set for the entire lifetime of the process --- there would be no way to test something else with no global default. But, I think this is fine, even though it means we now have a bunch of tiny files: it also allows us to run an individual benchmark against every combination of dispatch types, without having to run unrelated benches. This is potentially useful if (for example) someone is changing only the code for recording events, and not spans.
hawkw
added a commit
that referenced
this pull request
Jun 24, 2022
Currently, `tracing`'s benchmark suite benchmarks the same behaviors (e.g. creating a span, recording an event, etc) across a handful of cases: with no default dispatcher, with a global default, and with a scoped (thread-local) default. We use criterion's `benchmark_group` to represent each kind of dispatcher, and `bench_function` for each behavior being measured. This is actually kind of backwards relative to how Criterion is _supposed_ to be used. `bench_function` is intended for comparing different implementations of the *same* thing, with the `benchmark_group` representing what's being compared. If we inverted the structure of these benchmarks, Criterion would give us nicer plots that would allow comparing the performance of each dispatch type on the same task. This PR reorganizes the benchmarks so that each behavior being tested (such as entering a span or recording an event) is a `benchmark_group`, and each dispatch type (none, global, or scoped) is a `bench_function` within that group. Now, Criterion will generate plots for each group comparing the performance of each dispatch type in that benchmark. For example, we now get nice comparisons like this: 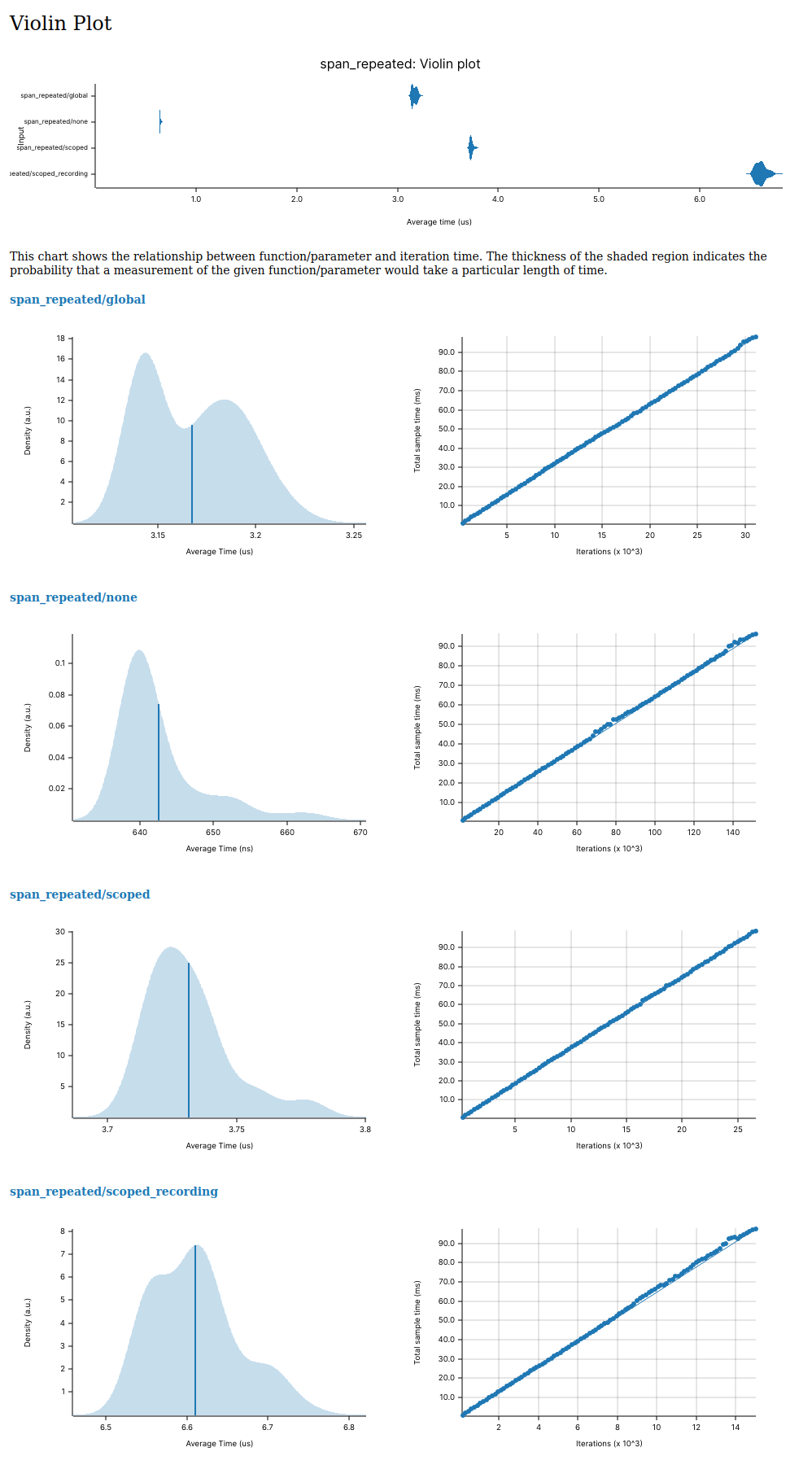 Unfortunately, this required splitting each benchmark type out into its own file. This is because, once we set the global default dispatcher within one benchmark group, it would remain set for the entire lifetime of the process --- there would be no way to test something else with no global default. But, I think this is fine, even though it means we now have a bunch of tiny files: it also allows us to run an individual benchmark against every combination of dispatch types, without having to run unrelated benches. This is potentially useful if (for example) someone is changing only the code for recording events, and not spans.
{kind=link}
kaffarell
pushed a commit
to kaffarell/tracing
that referenced
this pull request
May 22, 2024
Currently, `tracing`'s benchmark suite benchmarks the same behaviors (e.g. creating a span, recording an event, etc) across a handful of cases: with no default dispatcher, with a global default, and with a scoped (thread-local) default. We use criterion's `benchmark_group` to represent each kind of dispatcher, and `bench_function` for each behavior being measured. This is actually kind of backwards relative to how Criterion is _supposed_ to be used. `bench_function` is intended for comparing different implementations of the *same* thing, with the `benchmark_group` representing what's being compared. If we inverted the structure of these benchmarks, Criterion would give us nicer plots that would allow comparing the performance of each dispatch type on the same task. This PR reorganizes the benchmarks so that each behavior being tested (such as entering a span or recording an event) is a `benchmark_group`, and each dispatch type (none, global, or scoped) is a `bench_function` within that group. Now, Criterion will generate plots for each group comparing the performance of each dispatch type in that benchmark. For example, we now get nice comparisons like this:  Unfortunately, this required splitting each benchmark type out into its own file. This is because, once we set the global default dispatcher within one benchmark group, it would remain set for the entire lifetime of the process --- there would be no way to test something else with no global default. But, I think this is fine, even though it means we now have a bunch of tiny files: it also allows us to run an individual benchmark against every combination of dispatch types, without having to run unrelated benches. This is potentially useful if (for example) someone is changing only the code for recording events, and not spans.
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Currently,
tracing's benchmark suite benchmarks the same behaviors(e.g. creating a span, recording an event, etc) across a handful of
cases: with no default dispatcher, with a global default, and with a
scoped (thread-local) default. We use criterion's
benchmark_grouptorepresent each kind of dispatcher, and
bench_functionfor eachbehavior being measured.
This is actually kind of backwards relative to how Criterion is
supposed to be used.
bench_functionis intended for comparingdifferent implementations of the same thing, with the
benchmark_grouprepresenting what's being compared. If we inverted thestructure of these benchmarks, Criterion would give us nicer plots that
would allow comparing the performance of each dispatch type on the same
task.
This PR reorganizes the benchmarks so that each behavior being tested
(such as entering a span or recording an event) is a
benchmark_group,and each dispatch type (none, global, or scoped) is a
bench_functionwithin that group. Now, Criterion will generate plots for each group
comparing the performance of each dispatch type in that benchmark.
For example, we now get nice comparisons like this:

Unfortunately, this required splitting each benchmark type out into its
own file. This is because, once we set the global default dispatcher
within one benchmark group, it would remain set for the entire lifetime
of the process --- there would be no way to test something else with no
global default. But, I think this is fine, even though it means we now
have a bunch of tiny files: it also allows us to run an individual
benchmark against every combination of dispatch types, without having to
run unrelated benches. This is potentially useful if (for example)
someone is changing only the code for recording events, and not spans.